今回はPDFから表を抽出することができるtabulaライブラリを紹介します。
トヨタ自動車の23年3月期決算資料のPDF資料から営業収益、営業利益、税引前利益、当期利益、親会社の所有者に帰属する当期利益、当期包括利益をpandasの表として抜き出し、CSVファイルに出力してみました。
tabulaとは
Pythonのtabulaライブラリは、PDFファイルや画像ファイルから表データを抽出するオープンソースライブラリです。Javaで開発されたTabulaライブラリのPythonラッパーであり、使いやすさと高い精度で知られています。
主な機能としては以下のようなものがあります。
- PDFファイルや画像ファイルから表データを抽出
- 抽出した表データをpandasのDataFrameに変換
- 複数ページにわたる表データの抽出
- 表データのヘッダー行の自動認識
- 抽出対象となる表の範囲指定
tabulaの使い方
まずはtabulaのインストールを行います。
pip install tabula-py続いてライブラリのインポートを行います。
出力がpandasのデータベースとなるため、pandasも併せてインポートしておきます。
import pandas as pd
import tabulaこれでtabulaが使えるようになりました。
実際にPDFから表を抽出するには以下のようにコードを書きます。
dfs = tabula.read_pdf("PDFへのパス", pages = 'ページ数')ここでインポートがうまくいかず、以下のようなエラーが出る場合があります。
`java` command is not found from this Python process.Please ensure Java is installed and PATH is set for `java`
その場合はjavaがインストールされていない場合がありますので、以下URLよりJavaをインストールしてください。

tabulaによるデータ抽出
早速tabulaを使い、トヨタ自動車の23年3月期決算資料のPDF資料から利益情報を抜き出してみます。
import pandas as pd
import tabula
dfs = tabula.read_pdf("toyota_fiscal.pdf", pages = '2')
for df in dfs:
display(df)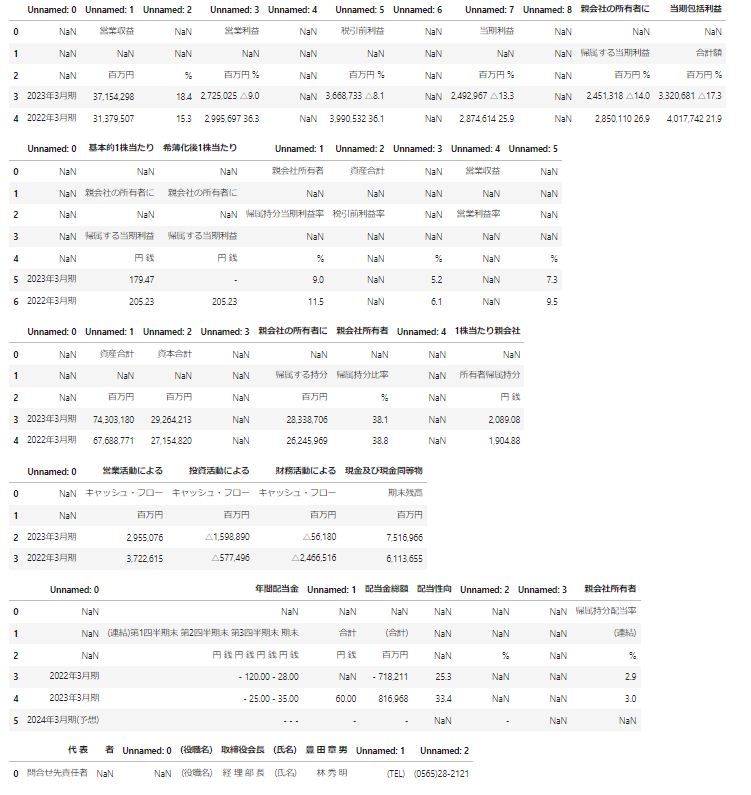
このように様々な情報を表形式で抜き出すことができました。
構造としては、一つの大きなデータフレームの中にPDF内の表が上から順番に入っているイメージです。
試しに一番初めの表を表示させてみます。
dfs[0]
表の抽出はうまくできているのですが、余計な行や列が含まれていることが分かります。
表として抜き出すため、データの成形を行います。
#不要な行の削除
df = df.drop(range(0,3)).reset_index(drop=True)
#不要な列の削除
df = df.dropna(axis = 1)
#各項目について、値を抜き出す
#期を抜き出す
df_term = df["Unnamed: 0"]
df_term
#営業収益
df_operating_revenue = df[["Unnamed: 1","Unnamed: 2"]]
df_operating_revenue.columns = ["営業収益", "増減"]
df_operating_revenue
#営業利益
df_operating_income = df["Unnamed: 3"].str.split(' ',expand=True)
df_operating_income.columns = ["営業利益", "増減"]
df_operating_income
#税引前利益
df_pretax_profit = df["Unnamed: 5"].str.split(' ',expand=True)
df_pretax_profit.columns = ["税引前利益", "増減"]
df_pretax_profit
#当期利益
df_net_income = df["Unnamed: 7"].str.split(' ',expand=True)
df_net_income.columns = ["当期利益", "増減"]
df_net_income
#親会社の所有者に帰属する当期利益
df_net_income_owners = df["親会社の所有者に"].str.split(' ',expand=True)
df_net_income_owners.columns = ["親会社の所有者に帰属する当期利益", "増減"]
df_net_income_owners
#当期包括利益
df_net_income_comprehensive = df["当期包括利益"].str.split(' ',expand=True)
df_net_income_comprehensive.columns = ["当期包括利益", "増減"]
df_net_income_comprehensive
#抜き出したデータを結合し、一つにする
df = pd.concat([df_term, df_operating_revenue, df_operating_income, df_pretax_profit, df_net_income, df_net_income_owners, df_net_income_comprehensive], axis=1)
df.to_csv("data/toyota_fisical.csv")
これできれいに各項目とその増減について抜き出すことができました。
まとめ
tabulaライブラリは、PDFファイルや画像ファイルから表データを抽出する際に非常に便利なライブラリです。使いやすく、高精度な抽出が可能なため、データ分析や資料作成など、さまざまな場面で活用できます。
データ成型の仕方を工夫すれば、様々なデータに適用させることができると思います。


コメント